Introduction to text analysis using R and quanteda
Purpose
This post introduces the capabilities of the R package quantida for for managing and analyzing textual data. quanted has been developed by Kenneth Benoit, Kohei Watanabe, and other contributors (Benoit, Kenneth, Kohei Watanabe, Haiyan Wang, Paul Nulty, Adam Obeng, Stefan Müller, and Akitaka Matsuo. (2018) “quanteda: An R package for the quantitative analysis of textual data”. Journal of Open Source Software. 3(30), 774. https://doi.org/10.21105/joss.00774; See also:http://quanteda.io/index.html).
This post builds heavely on the quanteda tutorial: https://tutorials.quanteda.io/
Data
For demonstration, we will use the corpus of United States Presidential State of the Union Addresses available through the sotu-package
# install packages
# install.packages("quanteda")
# install.packages("quanteda.textstats")
# install.packages("quanteda.textplots")
# install.packages("rvest")
# install.packages("stringr")
# install.packages("devtools")
# devtools::install_github("quanteda/quanteda.tidy")
#United States Presidential State of the Union Addresses package sotu
#install.packages("sotu")
# load packages
library("quanteda")
library("rvest")
library("stringr")
library("quanteda.textstats")
library("quanteda.textplots")
library("quanteda.tidy")
library(sotu)
library(dplyr)
Acquiring text
meta <- sotu_meta
glimpse(meta)
## Rows: 240
## Columns: 6
## $ X <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17…
## $ president <chr> "George Washington", "George Washington", "George Washing…
## $ year <int> 1790, 1790, 1791, 1792, 1793, 1794, 1795, 1796, 1797, 179…
## $ years_active <chr> "1789-1793", "1789-1793", "1789-1793", "1789-1793", "1793…
## $ party <chr> "Nonpartisan", "Nonpartisan", "Nonpartisan", "Nonpartisan…
## $ sotu_type <chr> "speech", "speech", "speech", "speech", "speech", "speech…
text <- sotu_text
glimpse(text)
## chr [1:240] "Fellow-Citizens of the Senate and House of Representatives: \n\nI embrace with great satisfaction the opportuni"| __truncated__ ...
state_of_union <- cbind(meta, text)
glimpse(state_of_union)
## Rows: 240
## Columns: 7
## $ X <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17…
## $ president <chr> "George Washington", "George Washington", "George Washing…
## $ year <int> 1790, 1790, 1791, 1792, 1793, 1794, 1795, 1796, 1797, 179…
## $ years_active <chr> "1789-1793", "1789-1793", "1789-1793", "1789-1793", "1793…
## $ party <chr> "Nonpartisan", "Nonpartisan", "Nonpartisan", "Nonpartisan…
## $ sotu_type <chr> "speech", "speech", "speech", "speech", "speech", "speech…
## $ text <chr> "Fellow-Citizens of the Senate and House of Representativ…
#Keep texts from Barak Obama and Donald Trump
data_sotu <- state_of_union %>%
filter(president == "Barack Obama" | president =="Donald Trump")
glimpse(data_sotu)
## Rows: 12
## Columns: 7
## $ X <int> 229, 230, 231, 232, 233, 234, 235, 236, 237, 238, 239, 240
## $ president <chr> "Barack Obama", "Barack Obama", "Barack Obama", "Barack O…
## $ year <int> 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 201…
## $ years_active <chr> "2009-2013", "2009-2013", "2009-2013", "2009-2013", "2013…
## $ party <chr> "Democratic", "Democratic", "Democratic", "Democratic", "…
## $ sotu_type <chr> "speech", "speech", "speech", "speech", "speech", "speech…
## $ text <chr> "Madam Speaker, Mr. Vice President, Members of Congress, …
data_sotu$president
## [1] "Barack Obama" "Barack Obama" "Barack Obama" "Barack Obama" "Barack Obama"
## [6] "Barack Obama" "Barack Obama" "Barack Obama" "Donald Trump" "Donald Trump"
## [11] "Donald Trump" "Donald Trump"
Creating a text corpus
data_corpus <- corpus(data_sotu)
# check the number of documents included in the text corpus
ndoc(data_corpus)
## [1] 12
Tokenizing a corpus
Next, we tokenize our text corpus. Typically, tokenization involves separating texts by white spaces. We tokenize the text corpus without any pre-processing using tokens().
toks_sotu <- tokens(data_corpus)
# let's inspect the first six tokens of the first four documents
print(toks_sotu, max_ndoc = 4, max_ntoken = 6)
## Tokens consisting of 12 documents and 6 docvars.
## text1 :
## [1] "Madam" "Speaker" "," "Mr" "." "Vice"
## [ ... and 6,737 more ]
##
## text2 :
## [1] "Madam" "Speaker" "," "Vice" "President" "Biden"
## [ ... and 8,145 more ]
##
## text3 :
## [1] "Mr" "." "Speaker" "," "Mr" "."
## [ ... and 7,735 more ]
##
## text4 :
## [1] "Mr" "." "Speaker" "," "Mr" "."
## [ ... and 7,830 more ]
##
## [ reached max_ndoc ... 8 more documents ]
tokens(data_corpus)
## Tokens consisting of 12 documents and 6 docvars.
## text1 :
## [1] "Madam" "Speaker" "," "Mr" "." "Vice"
## [7] "President" "," "Members" "of" "Congress" ","
## [ ... and 6,731 more ]
##
## text2 :
## [1] "Madam" "Speaker" "," "Vice"
## [5] "President" "Biden" "," "Members"
## [9] "of" "Congress" "," "distinguished"
## [ ... and 8,139 more ]
##
## text3 :
## [1] "Mr" "." "Speaker" "," "Mr" "."
## [7] "Vice" "President" "," "Members" "of" "Congress"
## [ ... and 7,729 more ]
##
## text4 :
## [1] "Mr" "." "Speaker" "," "Mr" "."
## [7] "Vice" "President" "," "Members" "of" "Congress"
## [ ... and 7,824 more ]
##
## text5 :
## [1] "Please" "," "everybody" "," "have" "a"
## [7] "seat" "." "Mr" "." "Speaker" ","
## [ ... and 7,568 more ]
##
## text6 :
## [1] "The" "President" "." "Mr" "." "Speaker"
## [7] "," "Mr" "." "Vice" "President" ","
## [ ... and 7,896 more ]
##
## [ reached max_ndoc ... 6 more documents ]
# check number of tokens and types
toks_sotu %>%
ntoken() %>%
sum()
## [1] 86965
toks_sotu %>%
ntype() %>%
sum()
## [1] 21696
Without any pre-processing, the corpus consists of 86,965 tokens and 21,696 types.
Pre-processing
toks_sotu_pros <- toks_sotu %>%
tokens(remove_punct = TRUE) %>%
tokens_tolower()
# check number of tokens and types
toks_sotu_pros %>%
ntoken() %>%
sum()
## [1] 76779
toks_sotu_pros %>%
ntype() %>%
sum()
## [1] 20299
Keywords-in-context
We can use tokens objects to identify the occurrence of keywords and their immediate context.
kw_america <- kwic(toks_sotu,
pattern = c("america"),
window = 2)
# number of mentions
nrow(kw_america)
## [1] 291
# print first 6 mentions of America and the context of ±2 words
head(kw_america, n = 6)
## Keyword-in-context with 6 matches.
## [text1, 255] States of | America | will emerge
## [text1, 325] have made | America | the greatest
## [text1, 1067] households in | America | will receive
## [text1, 2698] vision for | America | , as
## [text1, 3164] time for | America | to lead
## [text1, 3339] energy in | America | . That's
Text processing
We remove very frequent features and transform all words to lowercase. The code below shows how to adjust the object accordingly.
toks_sotu_pros <- data_corpus %>%
tokens(remove_punct = TRUE) %>%
tokens_remove(pattern = stopwords("en")) %>%
tokens_tolower()
New token object
Let’s inspect if the changes have been implemented as we expect by calling kwic() on the new tokens object.
kw_america_pros <- kwic(toks_sotu_pros,
pattern = c("america"),
window = 2)
# print first 6 mentions of America and the context of ±2 words
head(kw_america_pros, n = 6)
## Keyword-in-context with 6 matches.
## [text1, 109] united states | america | emerge stronger
## [text1, 136] qualities made | america | greatest force
## [text1, 458] working households | america | receive tax
## [text1, 1184] see vision | america | blueprint future
## [text1, 1404] either time | america | lead thanks
## [text1, 1494] renewable energy | america | need support
# test: print as table+
library(kableExtra)
##
## Attaching package: 'kableExtra'
## The following object is masked from 'package:dplyr':
##
## group_rows
kw_america_pros |> data.frame() %>%
dplyr::select(Pre = pre, Keyword = keyword, Post = post, Pattern = pattern) %>%
kbl(booktabs = T) %>%
kable_styling(latex_options = c("striped", "scale_down"), html_font = "Source Sans Pro", full_width = F)
| Pre | Keyword | Post | Pattern |
|---|---|---|---|
| united states | america | emerge stronger | america |
| qualities made | america | greatest force | america |
| working households | america | receive tax | america |
| see vision | america | blueprint future | america |
| either time | america | lead thanks | america |
| renewable energy | america | need support | america |
| built right | america | speaking auto | america |
| cost easy | america | easy necessary | america |
| causes bankruptcy | america | every 30 | america |
| promise education | america | global economy | america |
| make children | america | already made | america |
| goal 2020 | america | highest proportion | america |
| powerful example | america | ordered closing | america |
| united states | america | torture can | america |
| begun know | america | meet threats | america |
| meet without | america | shun negotiating | america |
| enduring spirit | america | quit someday | america |
| united states | america | thank | america |
| progress inevitable | america | always destined | america |
| hesitations fears | america | prevailed chose | america |
| like across | america | 2 years | america |
| united states | america | now house | america |
| wait long | america | put future | america |
| united states | america | hard may | america |
| kind energy | america | now grateful | america |
| global economy | america | must nation | america |
| support right | america | tonight set | america |
| million jobs | america | help meet | america |
| just competitors | america | sits sidelines | america |
| united states | america | one go | america |
| year 2000 | america | budget surplus | america |
| hopeful future | america | world work | america |
| 60 years | america | takes actions | america |
| corruption guinea | america | must always | america |
| values built | america | values allowed | america |
| united states | america | america | |
| leadership made | america | just place | america |
| predicting decline | america | still largest | america |
| world make | america | best place | america |
| revolution can | america | better anyone | america |
| google facebook | america | innovation just | america |
| produce jobs | america | overseas also | america |
| many nations | america | fallen ninth | america |
| nation builders | america | time treated | america |
| end decade | america | highest proportion | america |
| future rebuilding | america | attract new | america |
| d better | america | nation built | america |
| every part | america | digital age | america |
| infrastructure make | america | better place | america |
| goal competitive | america | submit proposal | america |
| united states | america | stands people | america |
| days founding | america | story ordinary | america |
| things idea | america | endures destiny | america |
| united states | america | america | |
| example think | america | within reach | america |
| educating people | america | attracts new | america |
| china meanwhile | america | productive weeks | america |
| choose stay | america | get hit | america |
| stay hire | america | third american | america |
| jobs right | america | send tax | america |
| level promise | america | always win | america |
| every family | america | able afford | america |
| jobs innovation | america | always new | america |
| can last | america | nearly 100 | america |
| chemicals use | america | develop resource | america |
| already positioned | america | world's leading | america |
| next decade | america | less pollution | america |
| infrastructure much | america | needs rebuilt | america |
| owner rural | america | selling products | america |
| great depression | america | built hoover | america |
| handouts copouts | america | built last | america |
| reduce deficit | america | built last | america |
| united states | america | achieve lesson | america |
| united states | america | position strength | america |
| source attacks | america | tide war | america |
| let doubt | america | determined prevent | america |
| made clear | america | pacific power | america |
| moral example | america | back anyone | america |
| anyone tells | america | decline influence | america |
| rio opinions | america | higher years | america |
| every event | america | remains one | america |
| cops firefighters | america | strong defend | america |
| watching back | america | time look | america |
| united states | america | america | |
| can know | america | moves forward | america |
| united states | america | tax reform | america |
| united states | america | american people | america |
| priority making | america | magnet new | america |
| making macs | america | things can | america |
| made right | america | can get | america |
| power capacity | america | generate even | america |
| new goal | america | cut half | america |
| partnership rebuild | america | attracts private | america |
| united states | america | start right | america |
| responsible homeowner | america | chance save | america |
| single child | america | something able | america |
| make sure | america | remains place | america |
| right away | america | better get | america |
| first job | america | place chance | america |
| hit towns | america | get communities | america |
| communities stronger | america | kind prosperity- | america |
| say confidence | america | complete mission | america |
| al qaida | america | continue lead | america |
| meet obligations | america | must also | america |
| reach see | america | must remain | america |
| voting experience | america | definitely needs | america |
| united states | america | america | |
| americans today | america | teacher spent | america |
| part help | america | wean foreign | america |
| communities across | america | fathers mothers | america |
| place invest | america | believe can | america |
| breakthrough year | america | 5 years | america |
| get ahead | america | now face | america |
| eager work | america | stand still | america |
| believe- believe- | america | success depend | america |
| can help | america | lead world | america |
| new jobs | america | past 5 | america |
| tomorrow edge | america | surrender federally | america |
| working today | america | closer energy | america |
| selling truck | america | knew make | america |
| business leader | america | join us | america |
| us stronger | america | fields full | america |
| need right | america | need get | america |
| women succeed | america | succeeds now | america |
| incredible success | america | americans overwhelmingly | america |
| economy good | america | every mayor | america |
| state legislator | america | say wait | america |
| yes give | america | raise give | america |
| half parents | america | point lives | america |
| choice tell | america | differently see | america |
| foreign partners | america | must move | america |
| state knows | america | always side | america |
| strong confident | america | can negotiate | america |
| advantage opportunities | america | alliance europe | america |
| god bless | america | things help | america |
| loves like | america | serves sergeant | america |
| remind us | america | never come | america |
| every citizen | america | want kids- | america |
| kids- rising | america | honest work | america |
| united states | america | america | |
| breakthrough year | america | economy growing | america |
| grateful service | america | endured grit | america |
| always propelled | america | forward 2 | america |
| young love | america | get much | america |
| hard times | america | rebekah ben's | america |
| planet today | america | number one | america |
| oil gas | america | number one | america |
| young children | america | creating slots | america |
| every worker | america | opportunity earn | america |
| working people | america | raise now | america |
| upgrade skills | america | thrived 20th | america |
| idea across | america | 2 years | america |
| free universal | america | high school | america |
| every ceo | america | let repeat | america |
| since 2010 | america | put people | america |
| know want | america | know third | america |
| reward invest | america | use savings | america |
| growth competitiveness- | america | needs go | america |
| united states | america | question whether | america |
| question whether | america | leads world | america |
| terrorists threaten | america | iraq syria | america |
| well today | america | stands strong | america |
| economy tatters | america | leads bluster | america |
| iran secures | america | allies including | america |
| fails alienating | america | allies making | america |
| said liberal | america | conservative america | america |
| america conservative | america | black america | america |
| america black | america | white america | america |
| america white | america | united states | america |
| united states | america | said seen | america |
| office seen | america | best seen | america |
| mission building | america | going arguments | america |
| believe best | america | share broad | america |
| united states | america | want grow | america |
| work remaking | america | laid new | america |
| change accelerate | america | big changes | america |
| idea threatening | america | control time | america |
| third keep | america | safe lead | america |
| united states | america | right now | america |
| trends unique | america | offend uniquely | america |
| say people | america | going work | america |
| tackling poverty | america | giving everybody | america |
| practices across | america | part brighter | america |
| discovery dna | america | thomas edison | america |
| washington carver | america | grace hopper | america |
| sally ride | america | every immigrant | america |
| new moonshot | america | can cure | america |
| save make | america | country cures | america |
| together keep | america | safe strong | america |
| getting stronger | america | getting weaker | america |
| united states | america | powerful nation | america |
| united states | america | help remake | america |
| exactly year | america | led coalition | america |
| parts central | america | africa asia | america |
| power says | america | always act | america |
| products made | america | support good | america |
| good jobs | america | tpp china | america |
| back latin | america | restored diplomatic | america |
| trying weaken | america | democracy grinds | america |
| live now | america | want make | america |
| kindness helped | america | travel far | america |
| right worth | america | know country | america |
| united states | america | thank | america |
| states citizens | america | tonight mark | america |
| allies find | america | ready lead | america |
| foe find | america | strong america | america |
| america strong | america | proud america | america |
| america proud | america | free 9 | america |
| history world | america | look like | america |
| crucial demand | america | must put | america |
| truly make | america | great dying | america |
| loved one | america | refused uphold | america |
| form inside | america | allow nation | america |
| ship products | america | many countries | america |
| ship products | america | charge nothing | america |
| going let | america | great companies | america |
| financially yet | america | enforce rule | america |
| national rebuilding | america | spent approximately | america |
| finally keep | america | safe must | america |
| braver fight | america | uniform blessed | america |
| kind friend | america | look heroes | america |
| expressing people | america | respects right | america |
| united states | america | know america | america |
| america know | america | better less | america |
| process rebuilding | america | willing find | america |
| can found | america | friends today | america |
| 250th year | america | see world | america |
| ask made | america | greater ever | america |
| action now | america | empowered aspirations | america |
| future believe | america | thank god | america |
| mission make | america | great americans | america |
| strong proud | america | since election | america |
| 350 billion | america | hire another | america |
| believe believe | america | can dream | america |
| american way | america | know faith | america |
| united states | america | want exciting | america |
| substantially watch | america | also finally | america |
| crumbling infrastructure | america | nation builders | america |
| family leave | america | regains strength | america |
| praying everyone | america | grieving please | america |
| security future | america | recent weeks | america |
| bill puts | america | first come | america |
| bring best | america | see vivid | america |
| sergeant peck | america | salutes terrorists | america |
| go friends | america | enemies america | america |
| america enemies | america | strengthen friendships | america |
| stay silent | america | stands people | america |
| threat pose | america | allies otto | america |
| labor returning | america | last june | america |
| place called | america | small cluster | america |
| people making | america | great long | america |
| god bless | america | goodnight | america |
| applause year | america | recognize two | america |
| 20th century | america | saved freedom | america |
| can compete | america | applause now | america |
| earth far | america | applause america | america |
| america applause | america | winning every | america |
| following lead | america | nation believes | america |
| show world | america | committed ending | america |
| financial wellbeing | america | moral duty | america |
| truly make | america | safe work | america |
| defeat aids | america | beyond applause | america |
| wealthiest south | america | state abject | america |
| booo president | america | founded liberty | america |
| renew resolve | america | never socialist | america |
| chants death | america | threatens genocide | america |
| old knew | america | prevail cause | america |
| yet unborn | america | us everything | america |
| must keep | america | first hearts | america |
| god bless | america | thank much | america |
| 3 years | america | now energy | america |
| two administrations | america | now gained | america |
| united states | america | indeed place | america |
| went serve | america | korea vietnam | america |
| job put | america | first next | america |
| high school | america | expand equal | america |
| aids epidemic | america | end decade | america |
| sick know | america | constantly achieving | america |
| new trees | america | around world | america |
| especially rural | america | better tomorrow | america |
| us keep | america | safe means | america |
| many cities | america | radical politicians | america |
| united states | america | sanctuary law-abiding | america |
| public schools | america | punish prayer | america |
| preachers pastors | america | celebrate faith | america |
| must remember | america | always frontier | america |
| pad ensure | america | first nation | america |
| witness tonight | america | land heroes | america |
| almighty god | america | place anything | america |
| can happen | america | place anyone | america |
| god bless | america | thank much | america |
Identifying multiword expressions
The package quanteda.textstats includes the function textstat_collocation() that automatically retrieves common multiword expressions.
tstat_coll <- data_corpus %>%
tokens(remove_punct = TRUE) %>%
tokens_remove(pattern = stopwords("en"), padding = TRUE) %>%
textstat_collocations(size = 2:3, min_count = 5)
# select the first 20 collocations
head(tstat_coll, 20)
## collocation count count_nested length lambda z
## 1 health care 55 44 2 8.096432 29.84438
## 2 united states 87 17 2 9.290649 29.57031
## 3 last year 46 36 2 5.714933 28.44516
## 4 american people 55 22 2 4.318872 26.54055
## 5 right now 41 29 2 4.946390 25.08424
## 6 high school 24 19 2 8.175795 22.86750
## 7 years ago 31 29 2 6.007038 22.75534
## 8 make sure 35 14 2 7.225183 22.35350
## 9 middle class 35 24 2 9.703782 22.22763
## 10 first time 27 6 2 5.187307 22.01583
## 11 clean energy 28 18 2 7.747080 21.62456
## 12 new jobs 36 24 2 4.073386 21.24003
## 13 took office 17 5 2 8.221849 20.39640
## 14 health insurance 19 16 2 7.193143 19.98062
## 15 small businesses 17 11 2 7.005867 19.52964
## 16 tax cuts 17 13 2 6.561422 19.20325
## 17 every day 18 16 2 5.335121 18.33243
## 18 working families 15 8 2 5.458811 17.86163
## 19 every american 27 17 2 3.837339 17.85800
## 20 immigration system 12 9 2 6.652498 17.73959
Document-feature matrix
Next, we transform our tokens object into a document-feature matrix (dfm). A dfm counts the occurrences of tokens in each document.
dfmat <- quanteda::dfm(toks_sotu_pros)
# most frequent features
topfeatures(dfmat, n = 10)
## american new america can now people us years
## 310 301 291 280 279 275 246 225
## americans jobs
## 220 214
# most frequent features by speaker
topfeatures(dfmat, groups = president, n = 10)
## $`Barack Obama`
## can new now america people us jobs american
## 222 217 214 203 196 184 179 177
## years work
## 161 155
##
## $`Donald Trump`
## american applause thank america new people one country
## 133 117 92 88 84 79 78 77
## americans tonight
## 76 73
Keyness
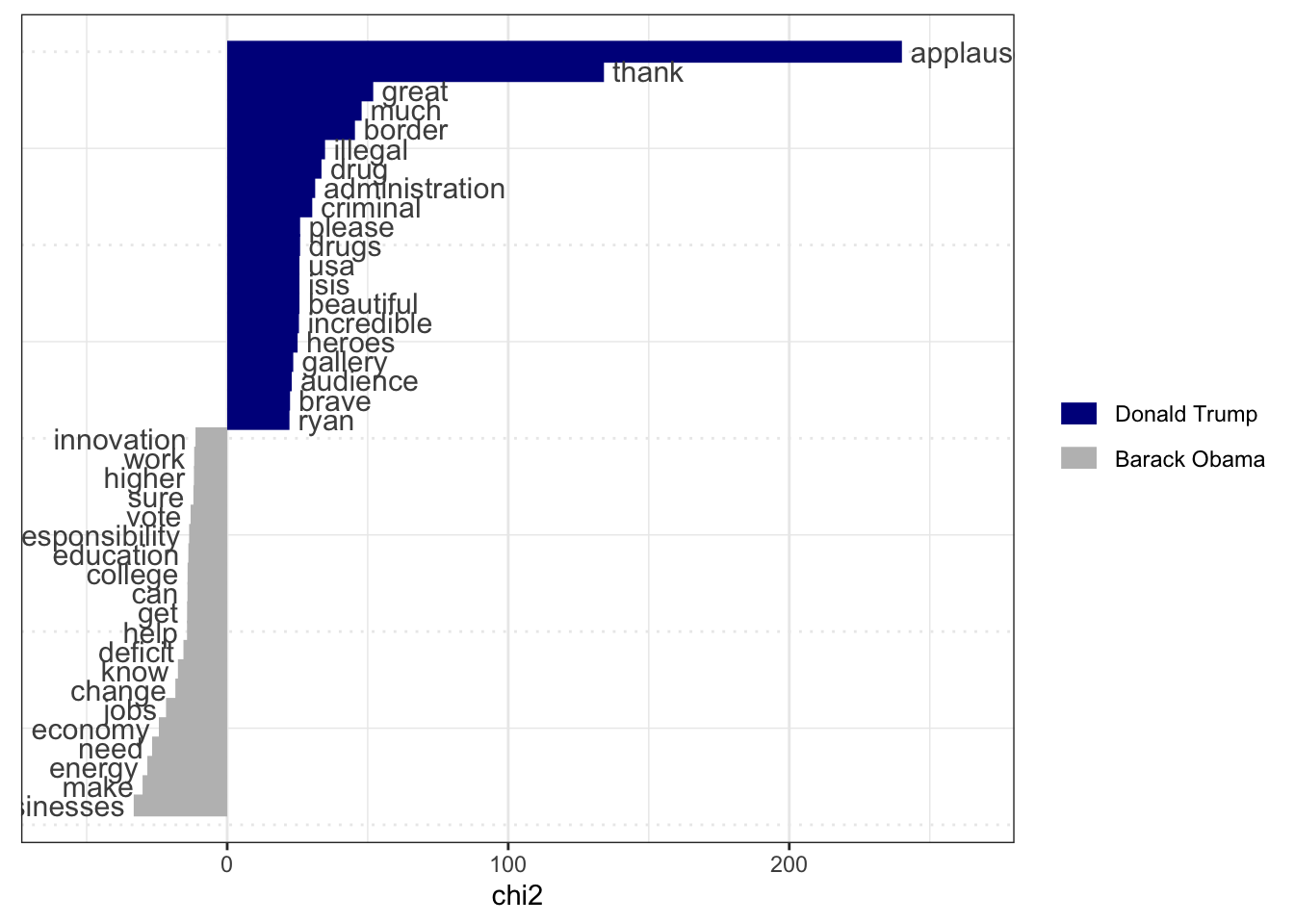
Keyness analysis allows compare frequencies of words between target and reference documents.
textstat_keyness()identifies features that occur differentially across different categories – in our case, Obama’s and Trump’s speeches. The function textplot_keyness() provides a way of visualize the results of the keyness analysis.
Keyness Figure
tstat_key <- dfmat %>%
quanteda::dfm_group(groups = president) %>%
quanteda.textstats::textstat_keyness(target = "Donald Trump")
textplot_keyness(tstat_key)
 ## Scaling document positions
## Scaling document positions
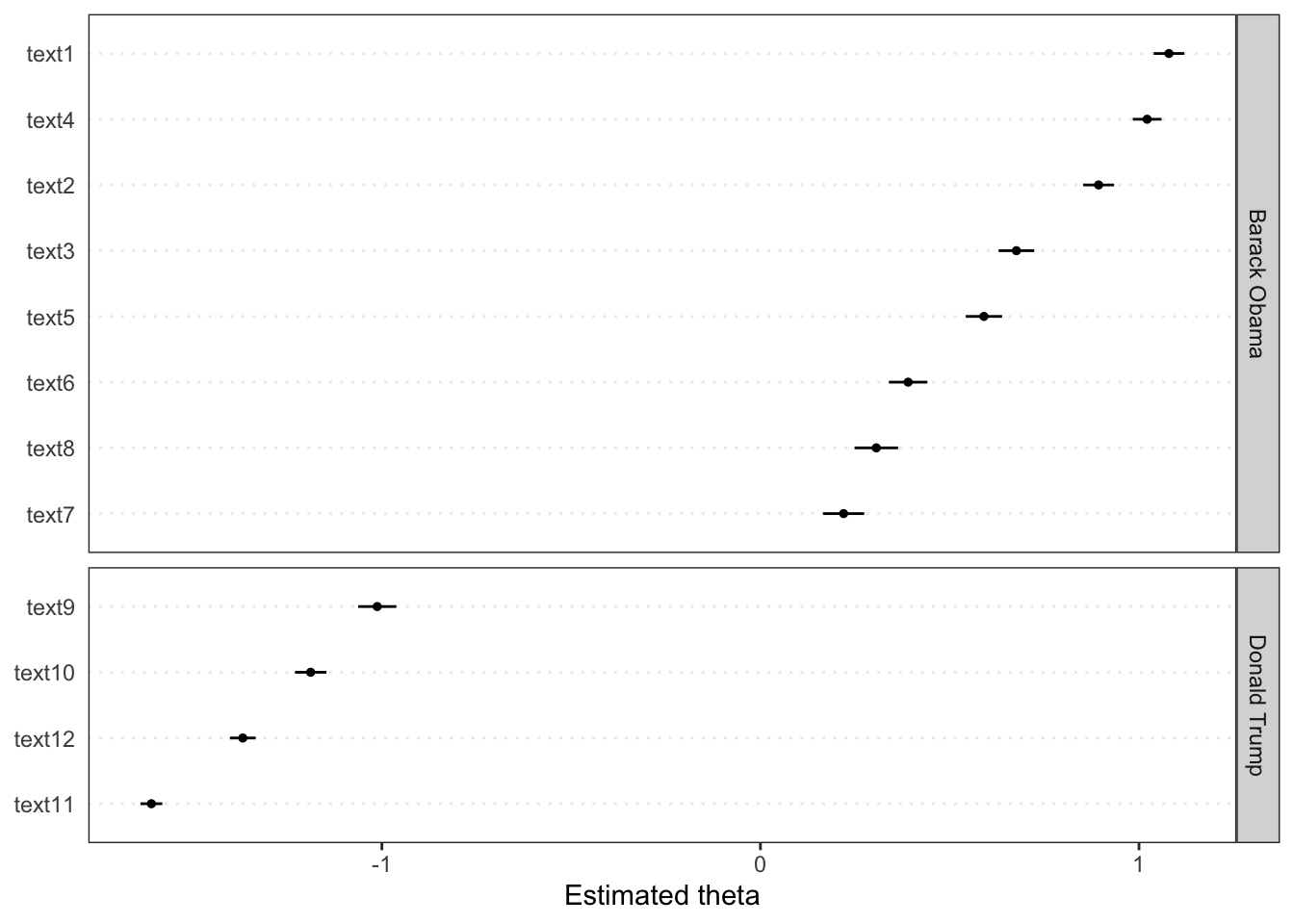
Wordfish is an unsupervised one-dimensional text scaling method (a Poisson scaling model of one-dimensional document positions), estimating the positions of documents solely based on the observed word frequencies. Here we estimate the ideological positions of speeches fro Barak Obama and Donald Trump.
library(quanteda.textmodels)
library(quanteda.textplots)
tmod_wf <- textmodel_wordfish(dfmat, dir = c(2, 1))
# plot the Wordfish estimates by president
textplot_scale1d(tmod_wf, groups = docvars(dfmat, "president"))
Topic model
We estimate a topic model for repectively Barak Obama and domnald Trump.
library(topicmodels)
dfmat_obama <- dfmat %>%
quanteda::dfm_subset(president %in% c("Barack Obama"))
dfmat_trump <- dfmat %>%
quanteda::dfm_subset(president %in% c("Donald Trump"))
tmod_lda_obama <- LDA(dfmat_obama, k = 10, method="Gibbs", control=list(seed=1948))
terms(tmod_lda_obama, 10)
## Topic 1 Topic 2 Topic 3 Topic 4 Topic 5
## [1,] "ones" "plan" "pay" "unemployment" "going"
## [2,] "skills" "budget" "control" "important" "lot"
## [3,] "students" "health" "built" "cory" "political"
## [4,] "development" "banks" "regulations" "workforce" "love"
## [5,] "prepare" "cost" "higher" "u.s.a" "democracy"
## [6,] "doubt" "care" "receive" "son" "especially"
## [7,] "poverty" "recovery" "return" "depend" "alone"
## [8,] "efforts" "responsibility" "gas" "ask" "isil"
## [9,] "others" "crisis" "brought" "worker" "gives"
## [10,] "process" "largest" "dignity" "iran's" "planet"
## Topic 6 Topic 7 Topic 8 Topic 9 Topic 10
## [1,] "wage" "spending" "can" "none" "past"
## [2,] "opportunities" "race" "new" "week" "want"
## [3,] "achieve" "goal" "now" "incentives" "sick"
## [4,] "5" "come" "america" "trillion" "rate"
## [5,] "need" "level" "people" "exports" "diplomacy"
## [6,] "15" "dream" "us" "human" "issues"
## [7,] "lower" "remember" "jobs" "wall" "networks"
## [8,] "rising" "nation" "american" "union" "earth"
## [9,] "changing" "internet" "years" "income" "forces"
## [10,] "skills" "willing" "work" "hundred" "childcare"
tmod_lda_trump <- LDA(dfmat_trump, k = 10, method="Gibbs", control=list(seed=1948))
terms(tmod_lda_trump,10)
## Topic 1 Topic 2 Topic 3 Topic 4 Topic 5 Topic 6
## [1,] "learn" "vice" "space" "applause" "days" "national"
## [2,] "honor" "soon" "deliver" "usa" "sanctuary" "foreign"
## [3,] "rebecca" "countries" "got" "put" "3" "obamacare"
## [4,] "greatest" "republican" "may" "secure" "reached" "department"
## [5,] "well" "signed" "lead" "wall" "aliens" "insurance"
## [6,] "credit" "crime" "making" "confront" "thanks" "allow"
## [7,] "perhaps" "continue" "poverty" "whether" "best" "truly"
## [8,] "legislation" "outdated" "york" "century" "lowest" "community"
## [9,] "senator" "steps" "tariffs" "prison" "u.s" "ryan"
## [10,] "increases" "change" "culture" "grace" "take" "us"
## Topic 7 Topic 8 Topic 9 Topic 10
## [1,] "american" "invest" "building" "look"
## [2,] "thank" "crossings" "ryan" "taking"
## [3,] "america" "restoring" "veterans" "longer"
## [4,] "new" "israel" "job" "walls"
## [5,] "country" "heroic" "serve" "something"
## [6,] "one" "250th" "kind" "liberty"
## [7,] "tonight" "women" "stands" "capitol"
## [8,] "people" "energy" "ms-13" "happen"
## [9,] "americans" "helping" "live" "childhood"
## [10,] "now" "thrive" "strength" "black"
Viisualize topic model
cf. https://www.tidytextmining.com/topicmodeling.html
library(tidytext)
obama_topics <- tidy(tmod_lda_obama, matrix = "beta")
library(ggplot2)
library(dplyr)
terms_per_topic <- 10
obama_top_terms <- obama_topics %>%
# filter(topic==6 | topic==8) %>%
group_by(topic) %>%
top_n(terms_per_topic, beta) %>%
ungroup() %>%
arrange(topic, -beta)
# top_n() doesn't handle ties -__- so just take top 10 manually
obama_top_terms <- obama_top_terms %>%
group_by(topic) %>%
slice(1:terms_per_topic) %>%
ungroup()
obama_top_terms$topic <- factor(obama_top_terms$topic)
obama_top_terms %>%
mutate(term = reorder(term, beta)) %>%
ggplot(aes(term, beta)) +
geom_bar(stat = "identity") +
facet_wrap(~ topic, scales = "free") +
theme(axis.text.x = element_text(angle = 90, hjust = 1)) +
coord_flip()
